Cara Membuat AI Chatbot Sederhana dengan Teknik RAG
- Rita Puspita Sari
- •
- 17 Mar 2025 23.48 WIB

Ilustrasi Chatbot AI
Kecerdasan buatan (AI) semakin menjadi bagian dari kehidupan kita. Hampir setiap hari, kita berinteraksi dengan Large Language Model (LLM) melalui chatbot, asisten virtual, atau fitur otomatis dalam aplikasi yang kita gunakan. AI membantu kita menulis lebih baik, menyusun email, bahkan menganalisis teks dalam hitungan detik.
Namun, meskipun AI sangat bermanfaat, ada keterbatasan yang perlu diperhatikan. LLM memiliki keterbatasan dalam memahami informasi terbaru atau data spesifik yang tidak termasuk dalam pelatihannya. Melatih ulang model AI untuk memahami data baru juga bukan perkara mudah proses ini bisa memakan waktu berbulan-bulan dan biaya jutaan dolar.
Lalu, bagaimana kita bisa membuat AI lebih cerdas tanpa harus melatih ulang model dari nol? Solusinya adalah Retrieval-Augmented Generation (RAG). Teknologi ini mengombinasikan pencarian informasi dari sumber eksternal dengan model bahasa besar, sehingga AI dapat memberikan jawaban yang lebih akurat dan relevan.
Mengapa LLM Saja Tidak Cukup?
LLM sangat berguna untuk tugas-tugas umum seperti meringkas teks, menulis kode, atau menjawab pertanyaan berbasis data yang tersedia hingga training cutoff date. Namun, jika kita membutuhkan informasi terbaru atau data spesifik untuk keperluan bisnis, model standar LLM bisa menjadi kurang akurat atau bahkan memberikan jawaban yang salah (hallucination).
Beberapa tantangan utama dalam penggunaan LLM adalah:
- Terbatas pada Data Pelatihan: Model hanya dapat menjawab pertanyaan berdasarkan data yang sudah dipelajari sebelumnya.
- Tidak Bisa Mengakses Informasi Baru: Jika ada informasi baru setelah model dilatih, AI tidak akan mengetahuinya kecuali diperbarui.
- Potensi Hallucination: AI bisa memberikan jawaban yang terdengar masuk akal tetapi sebenarnya tidak benar.
- Biaya Pelatihan yang Mahal: Melatih ulang LLM agar memahami data spesifik memerlukan sumber daya yang sangat besar.
Untuk mengatasi masalah ini, kita membutuhkan metode yang memungkinkan AI untuk mengakses informasi baru saat dibutuhkan, tanpa harus melatih ulang modelnya dari awal. Inilah peran penting dari Retrieval-Augmented Generation (RAG).
Apa Itu Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) adalah teknik yang menggabungkan pencarian informasi dengan model AI untuk menghasilkan jawaban yang lebih akurat. Dengan RAG, AI tidak hanya mengandalkan data pelatihannya, tetapi juga dapat mengambil informasi dari basis data eksternal, seperti dokumen perusahaan, database, atau sumber web terbaru.
Bagaimana Cara Kerja RAG?
Bayangkan Anda ingin menjawab pertanyaan tentang daftar pemenang Oscar tahun lalu, tetapi Anda sudah lupa. Untuk memberikan jawaban yang benar, Anda bisa:
- Mencari informasi online
- Membaca sumber yang relevan
- Meringkas jawaban untuk disampaikan
RAG bekerja dengan cara yang sama. Model AI mencari informasi dari sumber eksternal, mengambil data yang relevan, lalu menggunakannya untuk menghasilkan jawaban yang lebih akurat.
Secara teknis, RAG bekerja dalam tiga tahap utama:
- Pencarian Informasi: AI mencari data dari sumber eksternal seperti database atau dokumen.
- Pemrosesan Data: Informasi yang ditemukan diproses agar dapat digunakan oleh AI.
- Generasi Jawaban: LLM menggabungkan informasi yang diperoleh untuk memberikan jawaban yang lebih akurat.
Dengan metode ini, AI menjadi lebih fleksibel dan tidak hanya terbatas pada data pelatihannya.
Keunggulan Menggunakan RAG
Mengapa kita perlu menggunakan RAG? Berikut adalah beberapa manfaat utama dari teknologi ini:
- Meningkatkan Akurasi Fakta
RAG membantu mengurangi kesalahan informasi dengan mengacu pada sumber data yang lebih akurat dan terkini. - Memungkinkan AI Mengakses Informasi Eksternal
AI dapat mengambil data dari database perusahaan atau sumber web sehingga tidak hanya bergantung pada pelatihan awal. - Menghasilkan Jawaban yang Lebih Spesifik
AI dapat memahami konteks industri tertentu, seperti keuangan, hukum, atau kesehatan, dengan mengambil data dari sumber yang relevan. - Mengurangi Risiko Hallucination
Dengan mengambil data dari sumber terpercaya, RAG dapat mengurangi kemungkinan AI memberikan jawaban yang tidak benar atau menyesatkan. - Menghemat Biaya dan Waktu
Daripada melatih ulang model AI dari nol, kita bisa langsung memperkaya model dengan informasi baru menggunakan RAG.
Contoh Penerapan RAG: Asisten Pembaca PDF Berbasis AI
Untuk melihat bagaimana RAG bekerja dalam kehidupan nyata, mari kita bahas contoh aplikasi yang menggunakan teknologi ini:
Studi Kasus: Asisten Pembaca PDF Berbasis AI
Bayangkan Anda memiliki banyak dokumen PDF dan ingin mendapatkan informasi dari dokumen tersebut dengan cepat tanpa harus membacanya satu per satu. Dengan teknologi RAG, kita bisa membangun aplikasi yang memungkinkan pengguna mengunggah dokumen PDF dan mengajukan pertanyaan tentang isi dokumen tersebut.
Teknologi yang Digunakan
Aplikasi ini dapat dibuat menggunakan:
- Streamlit: Untuk membangun antarmuka pengguna.
- LangChain: Untuk mengelola interaksi dengan model bahasa.
- OpenAI GPT-4: Sebagai model AI utama.
- FAISS (Facebook AI Similarity Search) – Untuk pencarian dan pemrosesan dokumen.
Cara Kerja Aplikasi
- Dokumen PDF diunggah ke sistem
Dokumen dibagi menjadi potongan kecil agar mudah diproses. - Teks dari PDF diubah menjadi vektor menggunakan teknik embedding
Embeddings membantu AI memahami hubungan antar teks dalam dokumen. - Vektor teks disimpan dalam basis data
AI dapat dengan cepat mencari dan mengambil informasi dari database saat diperlukan. - Pengguna mengajukan pertanyaan tentang isi dokumen
AI menggunakan RAG untuk mengambil informasi dari database dan memberikan jawaban yang akurat.
Dengan cara ini, AI dapat menjawab pertanyaan tentang isi dokumen PDF tanpa perlu membaca seluruh dokumen.
Cara Membangun Aplikasi AI-Powered Document Q&A Menggunakan Python dan Streamlit
Berikut ini adalah cara membangun aplikasi berbasis AI yang memungkinkan pengguna mengunggah dokumen PDF, mengajukan pertanyaan, dan mendapatkan jawaban berbasis isi dokumen tersebut.
- Persiapan Data: Memuat dan Membagi Dokumen PDF
Langkah pertama dalam membangun aplikasi ini adalah mempersiapkan dokumen yang akan dianalisis oleh model AI. File PDF yang diunggah oleh pengguna perlu dipecah menjadi bagian-bagian kecil agar lebih mudah diproses dan diambil kembali ketika dibutuhkan.- Memuat Dokumen PDF
Untuk membaca file PDF, kita akan menggunakan PyPDFLoader dari library LangChain. Berikut adalah kode untuk memuat dan membagi dokumen menjadi beberapa bagian:
# Import library yang diperlukan
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
"""
Memuat file PDF dan membaginya menjadi beberapa bagian untuk memudahkan pengambilan data.
:param pdf: File PDF yang akan dimuat
:return: Daftar potongan teks dari file
"""
# Memuat file PDF
loader = PyPDFLoader(pdf)
docs = loader.load()
# Mengatur pemisahan teks dengan ukuran 500 kata dan overlap 100 kata agar konteks tidak hilang
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Memisahkan dokumen menjadi beberapa bagian
chunks = text_splitter.split_documents(docs)
return chunks
Kode di atas akan membaca isi file PDF, kemudian membaginya menjadi potongan teks sepanjang 500 kata dengan overlap 100 kata agar konteks tetap terjaga.
- Memuat Dokumen PDF
-
Membangun Aplikasi Web dengan Streamlit
Setelah dokumen siap, kita akan membangun antarmuka aplikasi menggunakan Streamlit. Aplikasi ini akan memungkinkan pengguna mengunggah file PDF dan mengajukan pertanyaan berdasarkan isinya.- Mengimpor Modul yang Diperlukan
Untuk membangun sistem ini, kita akan menggunakan berbagai modul dari LangChain, termasuk:- FAISS: Untuk menyimpan dan mengambil dokumen berdasarkan vektor embeddings.
- OpenAIEmbeddings: Untuk mengonversi teks menjadi representasi angka.
- ChatOpenAI: Untuk menjalankan model GPT.
- Streamlit: Untuk membangun antarmuka pengguna.
Berikut adalah kode untuk mengimpor semua modul:
# Import library yang diperlukan
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.chains import create_retrieval_chain
from langchain_openai import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from scripts.secret import OPENAI_KEY
from scripts.document_loader import load_document
import streamlit as st - Membuat Interface Aplikasi
Kode berikut akan membuat tampilan utama aplikasi dengan judul dan kotak unggah file:
Ketika pengguna mengunggah file PDF, sistem akan menyimpannya secara sementara, kemudian memprosesnya menggunakan fungsi load_document() yang telah dibuat sebelumnya.# Membuat aplikasi Streamlit
st.title("AI-Powered Document Q&A")
# Kotak unggah file PDF
uploaded_file = st.file_uploader("Unggah file PDF", type="pdf")
# Jika ada file yang diunggah
if uploaded_file:
# Menyimpan file sementara
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Memproses dokumen yang diunggah
chunks = load_document(temp_file)
# Menampilkan pesan bahwa dokumen sedang diproses
st.write("Memproses dokumen... ⏳")
- Mengimpor Modul yang Diperlukan
-
Mengonversi Teks ke dalam Representasi Numerik (Embeddings)
Model AI lebih memahami angka dibanding teks. Oleh karena itu, teks dalam dokumen perlu dikonversi menjadi representasi vektor numerik menggunakan embeddings.# Membuat embeddings (representasi numerik dari teks)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY, model="text-embedding-ada-002")
# Alternatif: Menggunakan Hugging Face
# from langchain_huggingface.embeddings import HuggingFaceEmbeddings
# embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# Membuat database vektor dari teks yang telah diproses
vector_db = FAISS.from_documents(chunks, embeddings)
Kode di atas menggunakan OpenAIEmbeddings untuk membuat representasi angka dari teks, yang kemudian disimpan dalam FAISS, sistem pencarian berbasis vektor. -
Membuat Sistem Pencarian Dokumen dan Model AI
Setelah teks dikonversi menjadi vektor, kita perlu membuat sistem yang memungkinkan pengguna mencari informasi berdasarkan pertanyaan mereka.- Membuat Pengambil Dokumen
Kode ini memungkinkan sistem menemukan bagian dokumen yang relevan berdasarkan pertanyaan pengguna.# Membuat objek untuk mengambil dokumen
retriever = vector_db.as_retriever() - Menggunakan Model GPT
Model GPT akan digunakan untuk menghasilkan jawaban berdasarkan dokumen yang telah diproses.# Menggunakan model OpenAI GPT-4o-mini
llm = ChatOpenAI(model_name="gpt-4o-mini", openai_api_key=OPENAI_KEY) - Membuat Prompt untuk Model AI
Sistem prompt ini memberi instruksi kepada model AI agar menjawab pertanyaan dengan tetap mempertimbangkan konteks dokumen.# Membuat prompt sistem
system_prompt = (
"Anda adalah asisten AI yang membantu menjawab pertanyaan berdasarkan konteks yang diberikan. "
"Jika Anda tidak tahu jawabannya, katakan bahwa Anda tidak tahu. "
"{context}"
)
# Membuat template prompt
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
- Membuat Pengambil Dokumen
-
Menghubungkan Semua Komponen
Terakhir, kita akan menggabungkan seluruh komponen untuk membentuk sistem pencarian dokumen berbasis AI.# Membuat rantai pemrosesan dokumen
question_answer_chain = create_stuff_documents_chain(llm, prompt)
# Membuat sistem RAG (Retrieval-Augmented Generation)
chain = create_retrieval_chain(retriever, question_answer_chain)
# Kotak input untuk pertanyaan pengguna
question = st.text_input("Ajukan pertanyaan tentang dokumen:")
if question:
# Menghasilkan jawaban berdasarkan input pengguna
response = chain.invoke({"input": question})['answer']
st.write(response)
Kode ini memungkinkan pengguna mengetik pertanyaan, dan sistem akan mencari jawaban berdasarkan isi dokumen yang telah diunggah.
Berikut adalah hasil running dari script diatas:
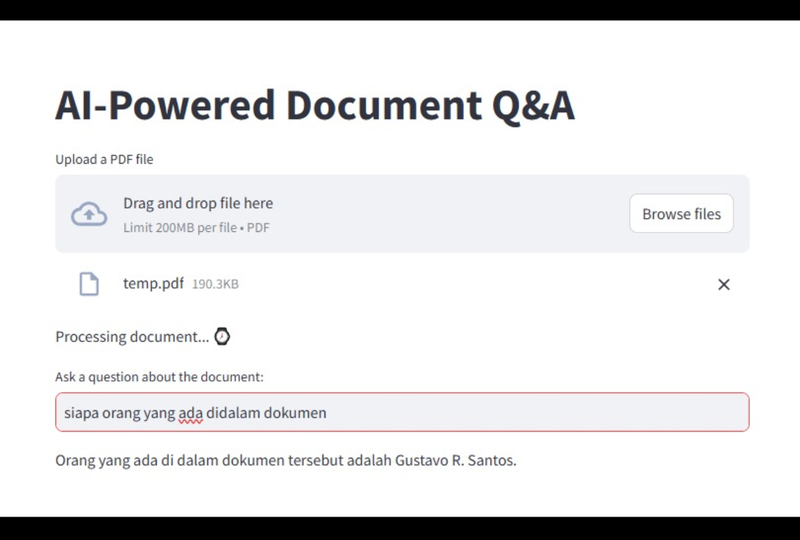
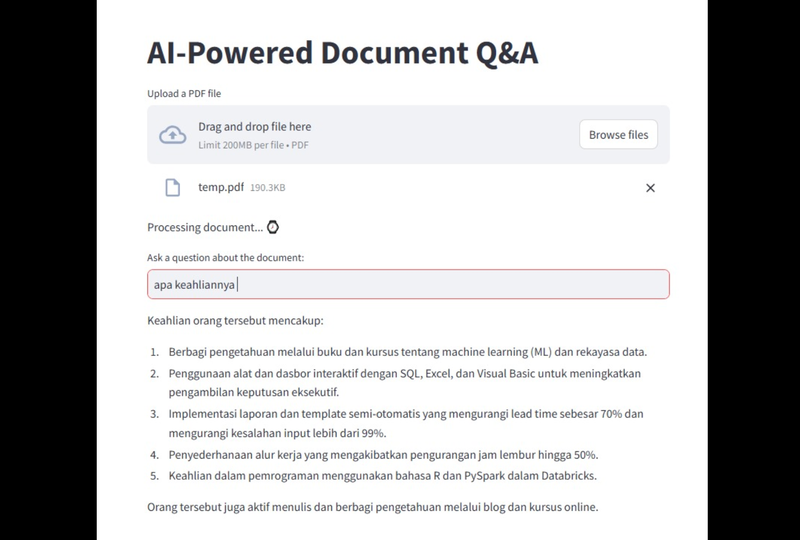
Kesimpulan
Kecerdasan buatan (AI), khususnya Large Language Model (LLM), telah menjadi bagian dari kehidupan sehari-hari. Namun, LLM memiliki keterbatasan dalam mengakses informasi terbaru dan spesifik, serta berisiko memberikan jawaban yang salah. Untuk mengatasi masalah ini, digunakan Retrieval-Augmented Generation (RAG), yang memungkinkan AI mencari dan menggabungkan informasi dari sumber eksternal agar jawaban lebih akurat.
Teknologi RAG diterapkan dalam berbagai solusi, termasuk asisten pembaca PDF berbasis AI, yang memungkinkan pengguna mencari informasi dalam dokumen tanpa membaca seluruh isinya.
Dalam proyek ini, kita telah membangun sistem pencarian dokumen berbasis AI yang memungkinkan pengguna mengunggah file PDF dan mencari informasi di dalamnya. Alur kerja sistem adalah sebagai berikut:
- Pengguna mengajukan pertanyaan: Sistem menerima input teks.
- Mencari dokumen yang relevan: Mencari dalam basis data vektor.
- Menambahkan konteks: Dokumen yang ditemukan ditambahkan ke input.
- Menghasilkan jawaban: LLM memproses input dan memberikan jawaban.
Dengan pendekatan ini, AI bisa digunakan untuk berbagai keperluan seperti membaca manual instruksi, dokumen keuangan, atau kontrak hukum.
Fitur tambahan yang dapat dikembangkan:
- Mendukung format lain (Word, TXT, dll.)
- Menyimpan riwayat pencarian pengguna
- Menggunakan model AI lokal untuk menghemat biaya API
Semoga artikel ini membantu memahami cara membangun sistem AI berbasis dokumen!






-(4).jpg)
-(3).jpg)